|
Microsoft Developing SQL Databases (70-762) Exam Page3(Dumps)
Question No:-11
|
DRAG DROP -
Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in the series.
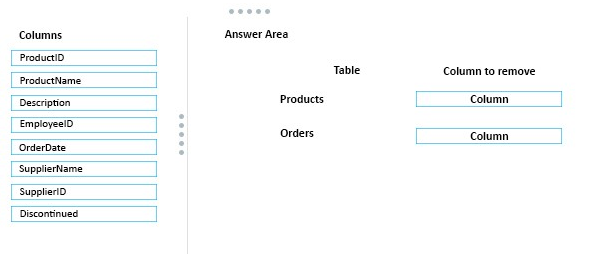
You have a database named Sales that contains the following database tables. Customer, Order, and Products. The Products table and the order table shown in the following diagram.

The Customer table includes a column that stores the date for the last order that the customer placed.
You plan to create a table named Leads. The Leads table is expected to contain approximately 20,000 records. Storage requirements for the Leads table must be minimized.
You need to begin to modify the table design to adhere to third normal form.
Which column should you remove for each table? To answer? drag the appropriate column names to the correct locations. Each column name may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
Select and Place:
HOTSPOT -
Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
You have a database that contains the following tables: BlogCategory, BlogEntry, ProductReview, Product, and SalesPerson. The tables were created using the following Transact SQL statements:

You must modify the ProductReview Table to meet the following requirements:
1. The table must reference the ProductID column in the Product table
2. Existing records in the ProductReview table must not be validated with the Product table.
3. Deleting records in the Product table must not be allowed if records are referenced by the ProductReview table.
4. Changes to records in the Product table must propagate to the ProductReview table.
You also have the following databse tables: Order, ProductTypes, and SalesHistory, The transact-SQL statements for these tables are not available.
You must modify the Orders table to meet the following requirements:
1. Create new rows in the table without granting INSERT permissions to the table.
2. Notify the sales person who places an order whether or not the order was completed.
You must add the following constraints to the SalesHistory table:
- a constraint on the SaleID column that allows the field to be used as a record identifier
- a constant that uses the ProductID column to reference the Product column of the ProductTypes table
- a constraint on the CategoryID column that allows one row with a null value in the column
- a constraint that limits the SalePrice column to values greater than four
Finance department users must be able to retrieve data from the SalesHistory table for sales persons where the value of the SalesYTD column is above a certain threshold.
You plan to create a memory-optimized table named SalesOrder. The table must meet the following requirments:
- The table must hold 10 million unique sales orders.
- The table must use checkpoints to minimize I/O operations and must not use transaction logging.
- Data loss is acceptable.
Performance for queries against the SalesOrder table that use Where clauses with exact equality operations must be optimized.
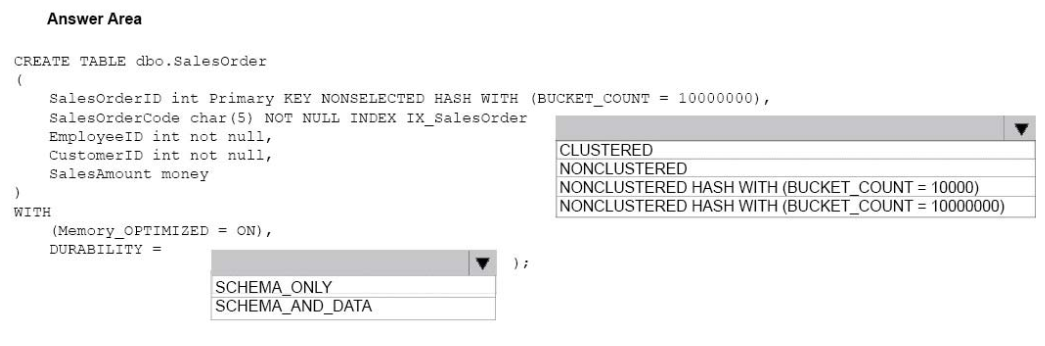
You need to create the Sales Order table
How should you complete the table definition? To answer? select the appropriate Transact-SQL segments in the answer area.
Hot Area:
Answer:-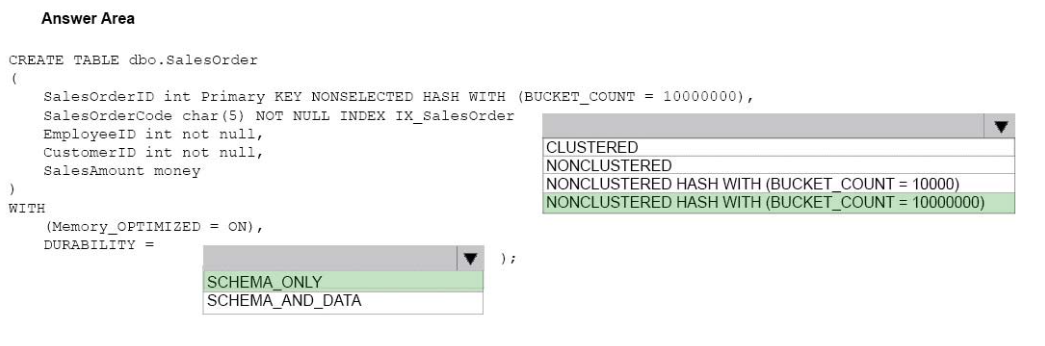
Box 1: NONCLUSTERED HASHWITH (BUCKET_COUNT = 10000000)
Hash index is preferable over a nonclustered index when queries test the indexed columns by use of a WHERE clause with an exact equality on all index key columns.We should use a bucket count of 10 million.
Box 2: SCHEMA_ONLY -
Durability: The value of SCHEMA_AND_DATA indicates that the table is durable, meaning that changes are persisted on disk and survive restart or failover.
SCHEMA_AND_DATA is the default value.
The value of SCHEMA_ONLY indicates that the table is non-durable. The table schema is persisted but any data updates are not persisted upon a restart or failover of the database. DURABILITY=SCHEMA_ONLY is only allowed with MEMORY_OPTIMIZED=ON.
Reference:-https://msdn.microsoft.com/en-us/library/mt670614.aspx
|
|
Question No:-12
|
HOTSPOT -
Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
You have a database that contains the following tables: BlogCategory, BlogEntry, ProductReview, Product, and SalesPerson. The tables were created using the following Transact SQL statements:

You must modify the ProductReview Table to meet the following requirements:
1. The table must reference the ProductID column in the Product table
2. Existing records in the ProductReview table must not be validated with the Product table.
3. Deleting records in the Product table must not be allowed if records are referenced by the ProductReview table.
4. Changes to records in the Product table must propagate to the ProductReview table.
You also have the following databse tables: Order, ProductTypes, and SalesHistory, The transact-SQL statements for these tables are not available.
You must modify the Orders table to meet the following requirements:
1. Create new rows in the table without granting INSERT permissions to the table.
2. Notify the sales person who places an order whether or not the order was completed.
You must add the following constraints to the SalesHistory table:
- a constraint on the SaleID column that allows the field to be used as a record identifier
- a constant that uses the ProductID column to reference the Product column of the ProductTypes table
- a constraint on the CategoryID column that allows one row with a null value in the column
- a constraint that limits the SalePrice column to values greater than four
Finance department users must be able to retrieve data from the SalesHistory table for sales persons where the value of the SalesYTD column is above a certain threshold.
You plan to create a memory-optimized table named SalesOrder. The table must meet the following requirments:
- The table must hold 10 million unique sales orders.
- The table must use checkpoints to minimize I/O operations and must not use transaction logging.
- Data loss is acceptable.
Performance for queries against the SalesOrder table that use Where clauses with exact equality operations must be optimized.
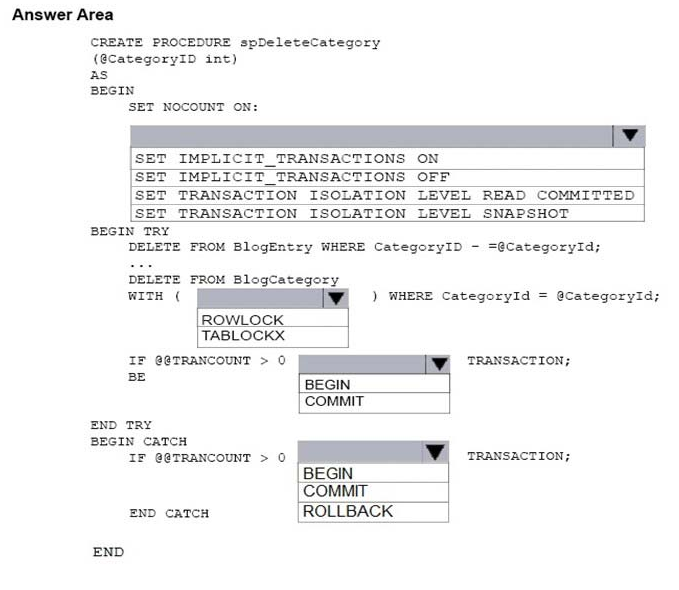
You need to create a stored procedure named spDeleteCategory to delete records in the database. The stored procedure must meet the following requirments:
1. Delete records in both the BlogEntry and BlogCategory tables where CategoryId equals parameter @CategoryId.
2. Avoid locking the entire table when deleting records from the BlogCategory table.
3. If an error occurs during a delete operation on either table, all changes must be rolled back, otherwise all changes should be committed.
How should you complete the procedure? To answer, select the appropriate Transact-SQL segments in the answer area.
Hot Area:
Answer:-
Box 1: SET TRANSACTION ISOLATION LEVEL READ COMMITTED
You can minimize locking contention while protecting transactions from dirty reads of uncommitted data modifications by using either of the following:
* The READ COMMITTED isolation level with the READ_COMMITTED_SNAPSHOT database option set ON.
* The SNAPSHOT isolation level.
With ROWLOCK we should use READ COMMITTED
Box 2: ROWLOCK -
Requirement: Avoid locking the entire table when deleting records from the BlogCategory table
ROWLOCK specifies that row locks are taken when page or table locks are ordinarily taken. When specified in transactions operating at the SNAPSHOT isolation level, row locks are not taken unless ROWLOCK is combined with other table hints that require locks, such as UPDLOCK and HOLDLOCK.
Box 3: COMMIT -
Box 4: ROLLBACK
|
|
Question No:-13
|
DRAG DROP -
You are analyzing the performance of a database environment.
Applications that access the database are experiencing locks that are held for a large amount of time. You are experiencing isolation phenomena such as dirty, nonrepeatable and phantom reads.
You need to identify the impact of specific transaction isolation levels on the concurrency and consistency of data.
What are the consistency and concurrency implications of each transaction isolation level? To answer, drag the appropriate isolation levels to the correct locations. Each isolation level may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
Select and Place:
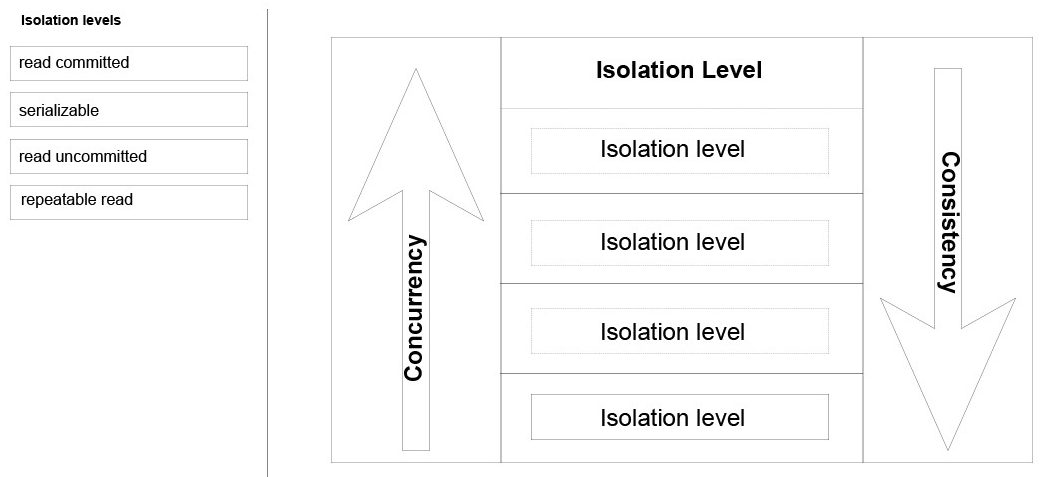
Answer:-
Read Uncommitted (aka dirty read): A transaction T1executing under this isolation level can access data changed by concurrent transaction(s).
Pros: No read locks needed to read data (i.e. no reader/writer blocking). Note, T1 still takes transaction duration locks for any data modified.
Cons: Data is notguaranteed to be transactionally consistent.
Read Committed: A transaction T1 executing under this isolation level can only access committed data.
Pros: Good compromise between concurrency and consistency.
Cons: Locking and blocking. The data can change when accessed multiple times within the same transaction.
Repeatable Read: A transaction T1 executing under this isolation level can only access committed data with an additional guarantee that any data read cannot change (i.e. it is repeatable) for the duration of the transaction.
Pros: Higher data consistency.
Cons: Locking and blocking. The S locks are held for the duration of the transaction that can lower the concurrency. It does not protect against phantom rows.
Serializable: A transaction T1 executing under this isolation level provides the highest data consistency including elimination of phantoms but at the cost of reduced concurrency. It prevents phantoms by taking a range lock or table level lock if range lock can't be acquired (i.e. no index on the predicate column) for the duration of the transaction.
Pros: Full data consistency including phantom protection.
Cons: Locking and blocking. The S locks are held for the duration of the transaction that can lower the concurrency.
Reference:-https://blogs.msdn.microsoft.com/sqlcat/2011/02/20/concurrency-series-basics-of-transaction-isolation-levels/
|
|
Question No:-14
|
DRAG DROP -
You are evaluating the performance of a database environment.
You must avoid unnecessary locks and ensure that lost updates do not occur.
You need to choose the transaction isolation level for each data scenario.
Which isolation level should you use for each scenario? To answer, drag the appropriate isolation levels to the correct scenarios. Each isolation may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
Select and Place:

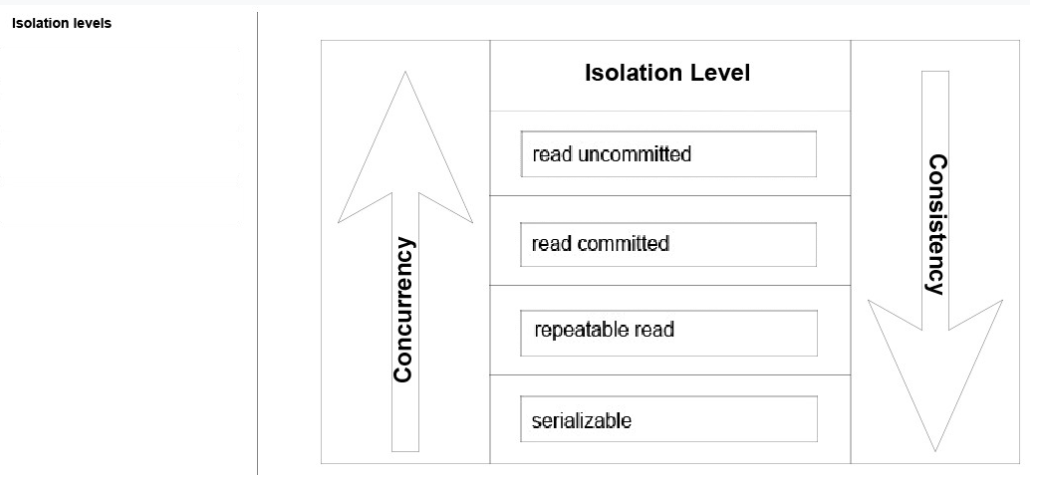
Answer:-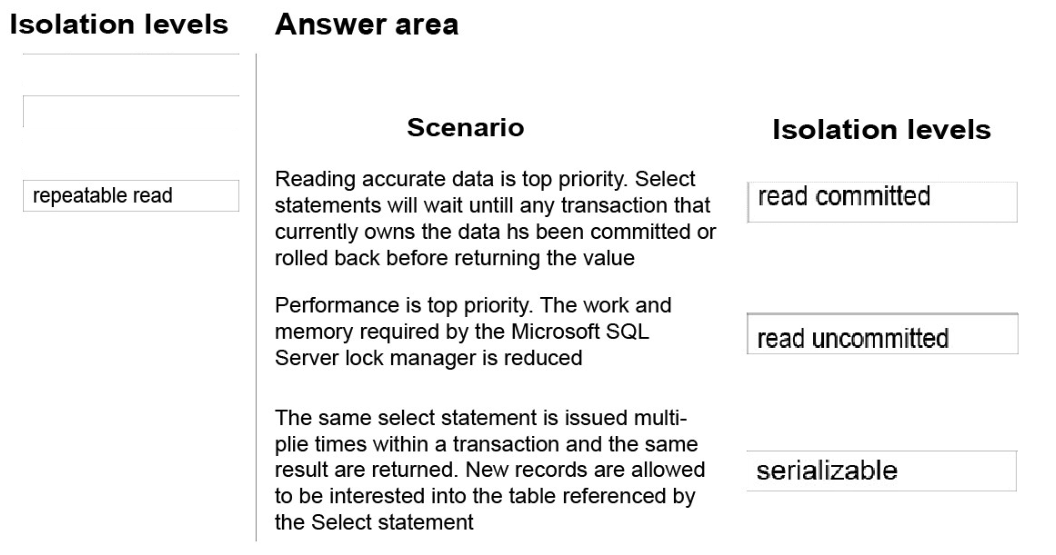
Box 1: Read committed -
Read Committed: A transaction T1 executing under this isolation level can only access committed data.
Pros: Good compromise between concurrency and consistency.
Cons: Locking and blocking. The data can change whenaccessed multiple times within the same transaction.
Box 2: Read Uncommitted -
Read Uncommitted (aka dirty read): A transaction T1 executing under this isolation level can access data changed by concurrent transaction(s).
Pros: No read locks needed to readdata (i.e. no reader/writer blocking). Note, T1 still takes transaction duration locks for any data modified.
Cons: Data is not guaranteed to be transactionally consistent.
Box 3: Serializable -
Serializable: A transaction T1 executing under thisisolation level provides the highest data consistency including elimination of phantoms but at the cost of reduced concurrency. It prevents phantoms by taking a range lock or table level lock if range lock can't be acquired (i.e. no index on the predicatecolumn) for the duration of the transaction.
Pros: Full data consistency including phantom protection.
Cons: Locking and blocking. The S locks are held for the duration of the transaction that can lower the concurrency.
Reference:-https://blogs.msdn.microsoft.com/sqlcat/2011/02/20/concurrency-series-basics-of-transaction-isolation-levels/
|
|
Question No:-15
|
DRAG DROP -
You have two database tables. Table1 is a partioned table and Table 2 is a nonpartioned table.
Users report that queries take a long time to complete. You monitor queries by using Microsoft SQL Server Profiler. You observe lock escalation for Table1 and Table 2.
You need to allow escalation of Table1 locks to the partition level and prevent all lock escalation for Table2.
Which Transact-SQL statement should you run for each table? To answer, drag the appropriate Transact-SQL statements to the correct tables. Each command may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
Select and Place:
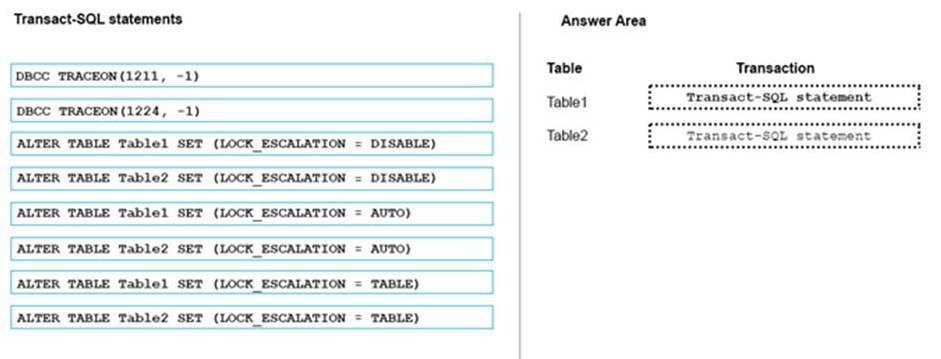
Answer:-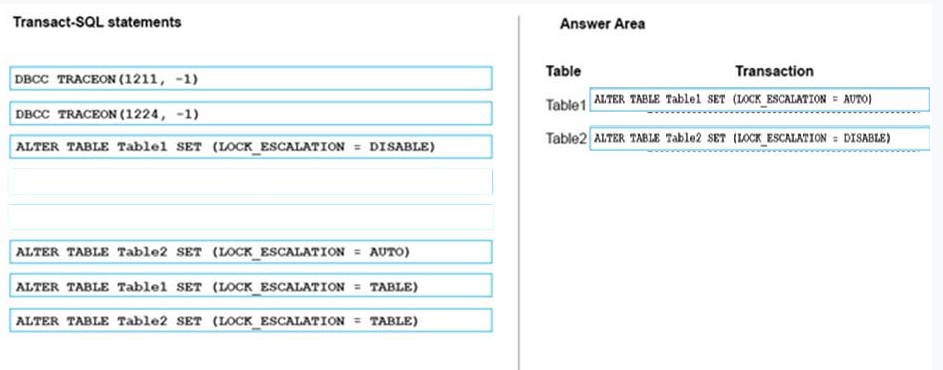
Since SQL Server 2008 you can also control how SQL Server performs the Lock Escalation "" through the ALTER TABLE statement and the property
LOCK_ESCALATION. There are 3 different options available:
Box 1: Table1, Auto -
The default option is TABLE, means that SQL Server *always* performs the Lock Escalation to the table level ""even when the table is partitioned. If you have your table partitioned, and you want to have a Partition Level Lock Escalation (because you have tested your data access pattern, and you don't cause deadlocks with it), then you can change the option to AUTO. AUTO means that the Lock Escalation is performed to the partition level, if the table is partitioned, and otherwise to the table level.
Box 2: Table 2, DISABLE -
With the option DISABLE you can completely disable the Lock Escalation for that specific table.
For partitioned tables, use the LOCK_ESCALATION option of ALTER TABLE to escalate locks to the HoBT level instead of the table or to disable lock escalation.
Reference:-http://www.sqlpassion.at/archive/2014/02/25/lock-escalations/
|
|
|